



转载:https://www.toutiao.com/article/7364595629895352883/
2024-04-21 23:25・界面快讯
最近,由清华大学基础模型研究中心联合中关村实验室研制的SuperBench大模型综合能力评测框架,正式对外发布2024年3月版《SuperBench大模型综合能力评测报告》。
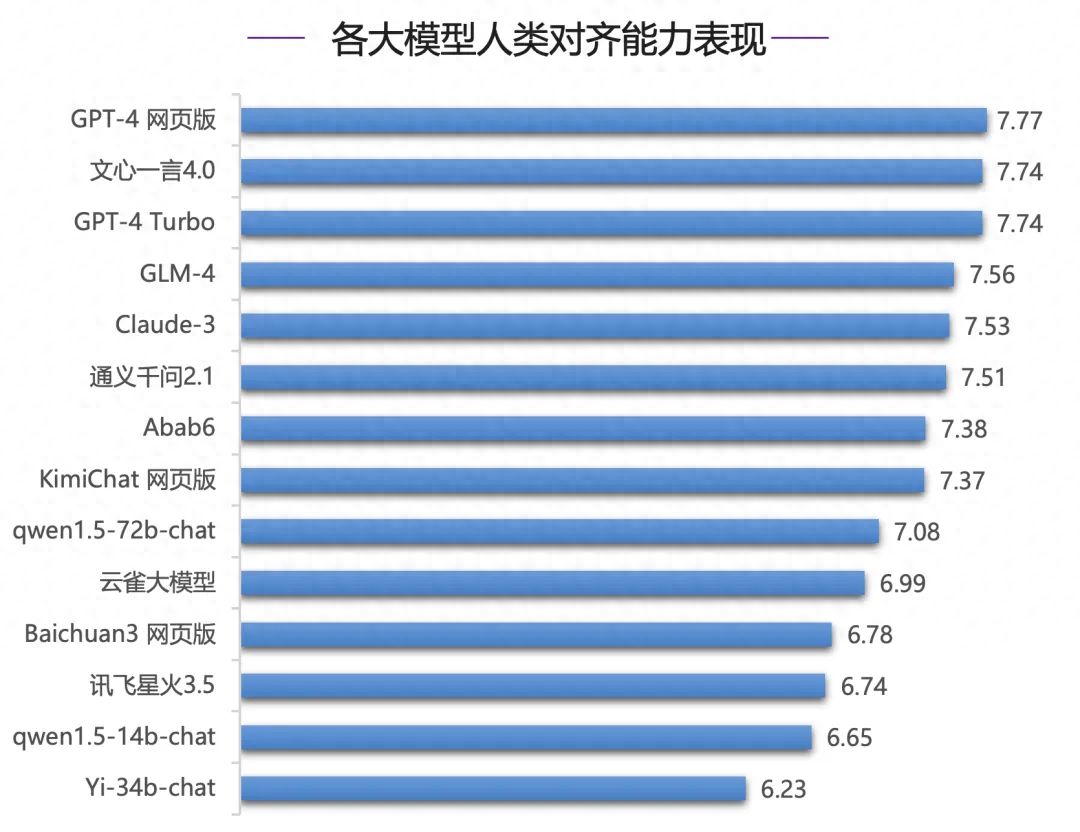
评测共包含了14个海内外具有代表性的模型,在人类对齐能力评测中,文心一言4.0表现位居国内第一,其中在中文推理、中文语言等评测上,文心一言分数领先,和其他模型拉开明显差距,中文理解上,文心一言4.0领先优势明显,领先第二名GLM-4 0.41分,GPT-4系列模型表现较差,排在中下游,并且和第一名文心一言4.0分差超过1分。
在语义理解中的数学能力上,文心一言4.0与Claude-3并列全球第一; GPT-4系列模型位列第四五,其他模型得分在55分附近较为集中,明显落后第一梯队;而在语义理解中的阅读理解能力上,文心一言4.0超过GPT-4 Turbo、Claude-3以及GLM-4拿下榜首。
在安全性评测上,国内模型文心一言4.0拿下最高分(89.1分),Claude-3仅列第四。
 相关论坛
相关论坛
 相关广告
相关广告

 拨打电话
拨打电话